











Towards Higher Onchain Scalability with the Unitrie

RSK was born in 2015 as an Ethereum-compatible Bitcoin sidechain. Back in 2016, when the RSK sidechain was still under development, we decided to improve and simplify its design by replacing one of the key components of Ethereum: the account trie, also called “world state” trie in Ethereum’s yellow paper. The world-state trie is the main database in the Ethereum-like blockchains, and its supporting data structure is called “Secure Modified Patricia Trie”. We designed a replacement state data structure, which evolved into what we now call the Unitrie.

Sergio Lerner (RSK Labs) Presenting the Unitrie in laBitConf (2016)
Some of the main properties of the (original) Unitrie are the following:
- The radix-16 tree is replaced with a radix-2 (binary) tree.
- Arbitrary length values can be stored in storage cells.
- All tries are combined, merging contract storage cells with account cells into a single bigger data-structure we called “Unitrie”.
- Links are augmented with last-update timestamps (“lastUpdateTimestamp” field), as a result, the Unitrie supports storage rent and automatic hibernation of nodes.
- Prefixes are stored in the parent node, for each of its children. This enables the removal of leaf nodes by hibernation in order to maximize data disposal. Also, this prevents cross-node side-effect on parallel transaction processing.
- Keys are “prefix secured” by a 10-byte (80 bit) hash prefix to prevent trie imbalance but still contain the full key (hash preimage) after the hashed prefix.
- Each node stores the size of its payload.
- Each non-leaf node stores the size of the its whole sub-tree.
- If a node is too small to deserve being stored independently in the database, it is embedded into its parent node. This saves the 32-byte hash digest used to reference the node.
Some benefits of the Unitrie are evident, but some are subtle. Here is a list of the main improvements:
- Simplification of the overall design.
- Reduction of the complexity of implementations, and therefore a reduction on the risk of consensus failures.
- Simplification of the design of Lightweight clients.
- Reduction of time for state synchronization (a.k.a. fast-sync/warp-sync), by making it more parallelizable and resilient to malicious state providers.
- Enabling simpler fraud proofs for SPV clients and for SPV bridges.
- Enabling simpler state garbage collection.
- Enabling per-storage-cell contract rent.
- Enabling per-storage-cell hibernation and wake-up.
- Enabling parallel execution with per-storage-cell collision detection.
- Enabling fast EXTCODESIZE queries without the need to retrieve the code data.
The Unitrie design was proposed by RSK Labs for the RSK blockchain and briefly presented in laBitConf, November 4-5, 2016. However, our main priority at that time, with RSK mainnet yet to be launched, was maintaining greater compatibility with Ethereum development tools, so we decided to postpone implementing the Unitrie and we only rolled out two critical changes to the trie data structure: the use of radix-2 instead of radix-16 and the storage of arbitrary length values. The use of radix-2 would enable the future migration to the Unitrie by doing a dynamic conversion of the trie, instead of a full database migration. This turned out to be a wise decision, as now we’re testing the fast migration of the whole tree structure dynamically, preserving most structural parts.
By the end of 2017, we were surprised to see Vitalik proposing a similar change to Ethereum in Ethereum forums. He also highlighted the benefits of a combined state tree. This supported our initial thesis that trie unification was an overall much better design.

Vitalik’s Proposal for a Combined State Trie (2017)
The Time Has Come
In January 2019, the RSK blockchain had its first birthday, and it marked one year with 100% uptime, so we decided to renew our efforts to push for the adoption of the Unitrie data structure in a following network upgrade. We edited and polished old RSKIPs and created new RSKIPs, and reference implementations. This article is part of our efforts to communicate how the RSK community will benefit from this proposed change. We updated RSKIP16, and we added RSKIP107, RSKIP108 and RSKIP109. RSKIP107 describes how trie nodes are compressed when stored. RSKIP108 describes how account addresses and storage cells addresses are mapped to trie keys. RSKIP109 re-defines storage cell write costs to incentivize the use of shorter storage addresses. We also implemented and tested all together, and we saw noticeable improvements in node performance and memory consumption, from state updates to synchronization. However, not everything went smoothly during tests. For example, we decided to exclude from the proposal the idea of moving the trie node prefixes to the parent nodes. The reason was that this change complicates the fast conversion between new and old tries relying on the similarities of the tree structures.
To reduce the risk associated with hard-forks, we think the best strategy is to split the changes into two consecutive network upgrades. The first, in Q2 2019 would include Unitrie, prefix-secured keys, payload-size cache, cache of tree sizes, and node compression on disk. The second, in Q4 2019, would include last-update timestamps for storage-rent. We’re postponing the storage-rent related features because the storage rent RSKIP is not final yet, and because the changes on the second network upgrade only affect new trie nodes created (it does not require the migration of the trie), while the first network upgrade requires the full migration of the trie.
A One of a Kind Network Upgrade
The full combination of account and storage nodes into a single tree can only be realized via a hard-fork, which means that the majority of miners need to upgrade to support this change, and all full nodes would also need to upgrade in order to stay synchronized. However, the Unitrie upgrade does not entail any relevant change to the platform economy. A slight decrease in storage cost will be implemented, which is the result of better matching the real storage cost with the charged amounts. This change will benefit all actors of the community. Also, the changes do not affect the security or privacy of the platform. Note that most development tools and wallets do not access the internals of the world-state directly, so they are not affected by this hard-fork.
The downside of the upgrade mechanism is that the old full node state-database will no longer be compatible with the new database. Creating a full node that is both compatible with the old trie and the new trie is a daunting task, with little benefit. The good news is that, because of the many performance improvements, the new full synchronization will only take a fraction of the time it previously took. Also, we’ve tested migrating the state database to the new format on node startup, so that nodes could maintain almost uninterrupted uptime after the software upgrade.
The Unitrie
The Unitrie combines account information with the storage cells of all contracts. It stores contract storage cells as leaves of a subtree rooted on the node corresponding to the contract’s storage address. It also partitions the contract information into several distinct tree sub-nodes. The following simplified diagram shows one account (ECDSA-controlled), which does not have any children, and a contract, which has one child node that stores the code of the contract, and a child sub-tree that contains the actual storage cells.
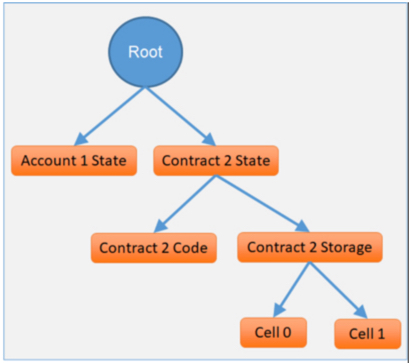
A sample Unitrie for a blockchain state
The combination of accounts and contract storage is not the only difference, the mapping of keys also changes. Let’s recap how the Ethereum account trie works: the trie is “secured” by using the hash digest of the account address as the key to retrieve a value. The nodes on the trie are not sorted by account addresses but by their hash digests. This key transformation is performed to prevent an attacker from spamming the data structure with values which share growing key prefixes which would degenerate the tree into a long chain. This attack could force a full node to perform certain lookups much slower, or to increase the size of certain trie inclusion proofs. In the Unitrie the keys are built from an 80-bit hash digest prefix, followed by the full plain account address. Only 80-bits are used to spread keys over the trie and keep it probabilistically balanced. Given that the impact of the tree degeneration attack is minimal, 80-bits are more than enough to disincentivize it. Said attack would require designing a special ASIC-based hash prefix brute-forcing hardware, which is very similar to a proof-of-work miner, and manufacturing millions of such “mining” boxes. If we imagine that state-of-the-art Bitcoin machines could perform an arbitrary 80-bit prefix pre-image search, then the attacker would need to spend about USD 6 Million in electricity to find collisions at the 80 different 80-bit positions to slightly degenerate the trie. Yet the impact on block processing time would be negligible (due to caches), and an inclusion proof for an unbalanced account would grow in size by only 2 Kbytes.
A benefit of this new mapping is that it preserves account address and storage cell addresses in the state, which enables many data-gathering applications to present meaningful information to the user without the need to index the whole blockchain. The following diagram depicts the transformation of account and storage addresses into a trie key:

Transformation of account and storage addresses into a trie key
To present the whole picture, we show how each type of data is mapped in the Unitrie:
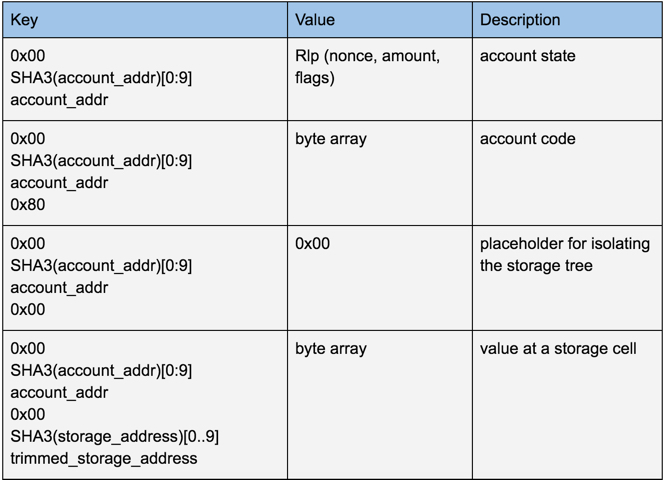
The first zero byte is used to store this tree into a special namespace. This enables future improvements to utilize other namespaces without the risk of collision. Some of the possible future improvements that could consume their own namespaces are:
- storing a special node that expands to a tree (or forest) of all previous block hashes to enable proofs of proofs of work (NiPowPow), and skip-lists.
- referencing account addresses with higher key-length (i.e., 256-bits) for enhanced security.
- referencing account addresses using double-hashed addresses, as defined by RSKIP32.
There are many differences between RSKIP16 Unitrie and Vitalik’s proposal. One difference is that the Unitrie doesn’t store the nonce and amount in different nodes, but keeps them together. There are several reasons for this:
- The serialization and deserialization of these two fields take little time, so further division causes loss of efficiency due to added disk-accesses to retrieve the account state.
- It is preferable to have some data at the specific address of the contract to be able to track contract changes in the future.
- Accounts can be used to “spam” the trie, so reducing the space consumed by accounts is important.
The Unitrie RSKIP Landscape
The Unitrie is defined by 9 RSKIPs (RSK Improvement Proposals). Each RSKIP describes a specific component of the Unitrie: structure, storage, key-mapping, storage rent, hibernation, gas costs. The following diagram depicts this separation:
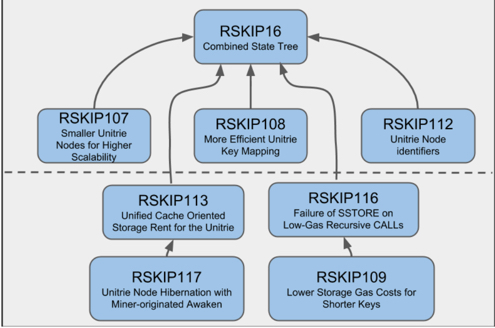
RSKIPs related to the Unitrie
In the first network upgrade, only 4 of the RSKIPs will be deployed, and the remaining will be delayed to the following network upgrade. This ensures the minimization of the migration risks.
Things left out of the Unitrie
During the original discussions regarding the Unitrie, we concluded that splitting the prefix from the node data into two different nodes would help maintain full immutability of untouched branches of the tree, and enable more fine-grained parallelization of tree updates. We called this scheme a PDB trie because nodes can be one of three disjoint types: Prefix, Data or Branch. Because switching to a PDB tree requires serious structural changes, it was left out from the Unitrie proposal. However, the PDB tree could be a topic for further research.
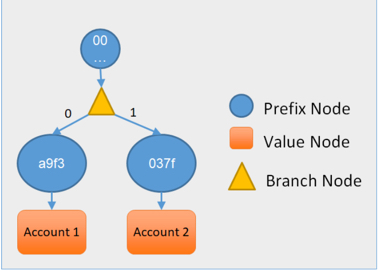
A Sample PDB tree used to store blockchain state
Now we’ll discuss in more detail each of the benefits of the RSK Unitrie.
Shorter Membership Proofs
By using a binary trie, instead of a radix-16 trie, membership proofs for accounts in the RSK trie are as short as possible, while the time required to validate its membership proofs is close to optimal. This enables decentralized lightweight nodes, running on mobile phones, to consume less bandwidth and less power. In the following example diagram, the radix-16 rie requires 30 pointers (donuts) and 3 nodes (circles) to prove the existence of a target node (blue circle). The radix-2 trie requires only 8 pointers and 8 nodes. When transmitted nodes do not require the transmission of parent references, because their references can be dynamically computed, and therefore the binary trie proof requires 26% of the space of the radix-16 trie.
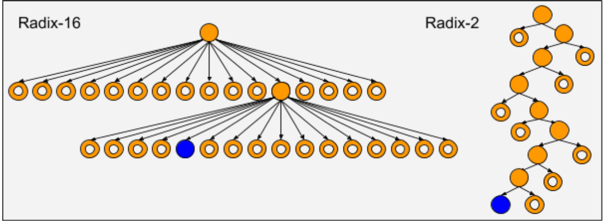
Comparison between a radix-16 and a radix-2 trie membership proof
State Size Reduction by the Compression of Account nodes
Accounts in the Unitrie do not need to store the “storage” trie root hash digest nor the code hash digest, this means that almost 60% of the account data is removed from the state. For instance, an account that stores 1 RBTC consumes about 38 bytes, instead of the 104 bytes consumed in Ethereum. The following diagram shows the approximate space savings of removing the unnecessary fields.
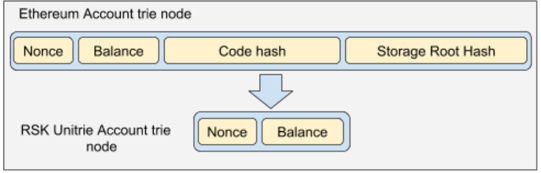
Compression of account nodes by removing unnecessary fields
State Size Reduction by Embedding Small Nodes
For child nodes whose size is lower than ~44 bytes (exact value TBD), the Unitrie provides the feature to embed them directly into parent nodes. This feature is described in the RSKIP107. As most accounts end up having nodes with sizes ranging from 31 to 41 bytes, this means that most accounts will be embedded in parent nodes. This reduces account overhead by 62%. The size reduction for accounts provided by node embedding combined with shorter account records reaches 81%, and it not only reduces the time to synchronize and the resource requirements of a full node, but also reduces the risks of a DoS attack that spams the state with account creations. The following example diagram shows how a node having two child nodes in the Ethereum trie is converted to a single node with its child embedded in the Unitrie.
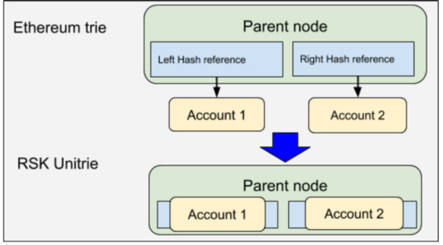
Embedding two small nodes into their parent
State Size Reduction and Lower Gas Cost by the Compression of Storage Cell Keys
Our RSKIP108 describes how storage cells can be compressed when the storage keys have long zero prefixes. Cells that have single byte addresses and store single bytes can be compressed to as low as 10% of the previous uncompressed size, because their small size also enables node embedding. To incentivize users to use compressed storage, RSKIP109 updates the cost of write operations to the contract storage. For example, storing 0x01 at address 0x00 would consume as low as 5460 gas units, instead of 20K, as in Ethereum. The following diagram depicts the different keys used in Ethereum and in the Unitrie, for storage cell address 0x01.
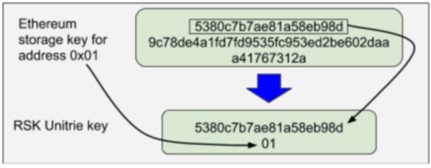
Example key storage compression
Better Scalability when Combined with Parallel Processing of Transactions
Our RSKIP04 proposes the parallel processing of transactions in order to reduce block processing time. By reducing block processing time, we can propagate blocks faster and improve consensus. It also means that we can put more transactions into blocks without delaying block propagation. In general, higher block propagation latency benefits the largest mining pools over the smaller ones, so knowing that we’re scaling without reducing decentralization is a reassuring fact. However, the blockchain can only benefit from parallel transaction processing if transactions can be split into non-overlapping sets in terms of contract state access. If all transactions are calling a single token contract, then that contract forces the serialization of the transactions and becomes the bottleneck. One solution, specified in RSKIP59 is to design contracts so that contract storage cells are moved into sub-contracts, creating parent-child relations. Then token balances for different users are stored in different contracts. Still, that solution requires redesigning and reimplementing contracts forcing the use of particular design patterns to enable scalability. However, the Unitrie may solve the problem without the associated hurdle of using new patterns. The Unitrie enables the simplified detection of concurrent accesses to storage cells, instead of only detecting concurrent accesses of full contracts. This means that as long as two transactions do not write the same storage cells (or one reads a cell that the other has written), both can be executed concurrently. For example, ERC20 contracts typically only change cells related to the source and destination accounts, therefore these contracts would get immediate parallelization capabilities with cell-level detection. While the same functionality could also be achieved without the Unitrie, the Unitrie simplifies the write collision detection algorithm enormously. As an example, the following diagram depicts two threads processing transactions. The first thread modifies a cell of a contract C (pointed by the violet arrow), which is not affected by thread 2. Thread 2, in turn, modifies two other cells from the same contract, which do not affect the cell modified by thread 1.
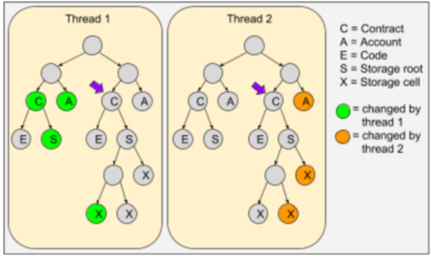
Two execution threads modifying the same contract storage
Better Fairness when Combined with Storage Rent
One consequence of the Ethereum design is that it enables gas arbitrage, by which users can pre-buy and occupy storage cells without storing any useful data, just to empty them at a later time in order to recover part of the gas used to buy them in the first place and to sell this gas to third parties. Another unintended consequence is that Ethereum requires a high up-front payment for using new storage cells because this payment mostly accounts for everlasting storage and liveness assurance for the key/value pair.
Storage rent mitigates both problems. The most discussed and accepted form of storage rent requires users that interact with a contract to pay a fee proportional to the time said contract was inactive, and proportional to the memory space consumed by the contract during the inactivity time. The RSKIP61 proposes the use of contract rent to prevent some undesired consequences of the original EVM design that affect platform fairness. Although this provides probabilistic fairness, it’s coarse-grained and does not work well in edge cases. A crowd-owned contract that stores millions of key/value pairs but is seldom used will put an excessive storage rent burden on the first user to call it after a long inactivity period. The Unitrie simplifies the task of tracking last access times for individual storage cells so that storage rent can become fine-grained, allowing a contract to pay rent only for the cells involved in a call execution. This simplification, specified in RSKIP113, results from all nodes being treated equal, so account, code, and storage cells can consume rent when they are accessed.
Increased Integrity with Simpler State Garbage Collection
State Garbage Collection is the removal of old state-data that will never be referenced again under normal conditions because it has been overwritten. On exceptional events, such as a significant blockchain reorganization, this data can be recomputed by re-executing the old blocks from a pre-computed state checkpoint. However, garbage collection on Ethereum is non-trivial because it must be applied to many separate databases (or tries), one for every active contract. Using the Unitrie means that garbage collection is applied to a single database, reducing risks of thread interruptions that could alter the database during garbage collection and leave it in an incoherent state.
Faster and Simpler State Synchronization
There are many applications that need to query the state of the blockchain at a particular block height, from lightweight wallets to blockchain bridges. The binary structure of the Unitrie provides minimum space consumption and maximum performance for retrieving and proving the membership of data in the state. It also reduces the complexity of network commands involved in the transmission of state information.
However, most importantly, the Untrie enables fast and parallel download of state information to perform a “Fast Sync” or a “Warp Sync.” Nodes can retrieve state information more efficiently if all the information is stored in a single trie. As the Unitrie stores the number of bytes consumed by the subtree rooted at each node, the Unitrie data structure supports size-range queries. This can be used by peers to request trie “packets” of a specific size, starting at any byte offset. Therefore, requests can be parallelized in a well load-balanced manner. For example, a node may collect state information from 10 nodes, and request the byte range 0K to100K to the first, 100K to 200K to the second, and so on. This allows the creation of a sync-mode that combines the benefits of fast-sync (immediate validation of returned data) with the benefits of warp-sync (retrieving large data chunks from multiple sources simultaneously). The following diagram shows an example Unitrie displaying node subtree sizes. The trie can be split into three chunks containing an almost equal amount of data each, each to be requested to a different peer. Even if the requestor doesn’t know the contents and limits of each chunk, the chunks’ sizes are known to her in advance. Each chunk can be efficiently and independently verified when received. Some internal nodes are included in more than one chunk, to enable verification.
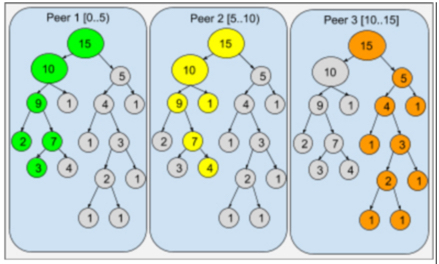
A state Unitrie split in three independently verifiable chunks
Yet another huge benefit of the Unitrie is that by storing the trie node size, a network node can show the state synchronization completion percentage and estimate the time remaining to finish the synchronization.
Smaller Blockchain Through Automatic Code Deduplication
By combining storage cells and code into a single content-addressed database, nodes that contain the same key/value are stored only once in the database. This provides automatic data deduplication, which, in case of contract code, can reduce the blockchain size without requiring a separate deduplication mechanism or using data compression techniques. Code nodes in the trie will always contain the same prefix (0x80); hence the same code implies the same node hash and the same storage.
Faster EXTCODESIZE Execution
Every Unitrie node contains a field that caches the size of the data stored in that node. In the Ethereum trie, querying the size of the node data forces the data to be fetched from the database. The Unitrie can respond to size queries, such as the ones generated by the EXTCODESIZE opcode, by querying this new field, and without fetching the code from hard disk. The EXTCODESIZE opcode has been used in the past to perform DoS attacks on certain Ethereum implementations, and the Unitrie provides immunity to this attack.
Details of the Upgrade Method
No blockchain has ever performed an upgrade that changes the state database when this database is committed into the block header. Therefore, the upgrade will be the first of its kind. Essentially the upgrade occurs in two phases. The new software release will compute the new trie root, but still derive the old trie root using a dynamic algorithm that structurally converts the new state trie to the old trie on-the-fly, followed by a hard-fork where the new state root is committed and verified, and dynamic conversion will not occur anymore. In fact, not only the state trie must be converted, but also the transaction and receipt tries.
Several events must occur for a successful network upgrade. A new version of the full node software will be released at time R. The new release contains periodic checkpoints from the genesis block to a specific block at time C. Time C occurs before time R. Then there is an interval in which nodes will upgrade before the hard-fork at time H. The following diagram represents the timeline:
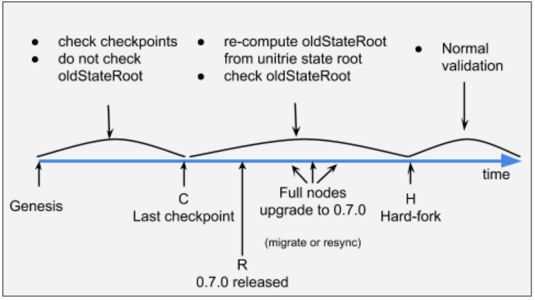
The timeline of a network upgrade for the Unitrie
When the new release (that we’ll call 0.7.0) is installed, a full node must rebuild its state database according to the new rules. It can either migrate the current state or recompute the state by re-processing all blocks from the genesis to the best chain tip. For the RSK upgrade, we opted for the re-processing. This ensures all full nodes’ databases are perfectly in-sync, even if the prior database was previously corrupted somehow.
The event C is chosen so that it occurs about two weeks before the hard-fork. Users should upgrade their full node software after release date R but before hard-fork date H. During the C-H period, nodes will compute both the old and the new trie state-roots. The old state-root will be computed dynamically from the new state trie. Lightweight nodes (a.k.a. SPV nodes) may decide not to validate state roots during this short interval to reduce CPU load. This is because lightweight nodes follow the hashrate anyway. Also, nodes can reduce validation overhead during this period by, for example, verifying 1 of every 10 state roots commitments during the C-H interval. However, the first block after the hard-fork will no longer compute or validate old state-roots. If accepted by the community, we expect a very clean hard-fork event.
Summary
The Unitrie, proposed by RSK back in 2016, is a notable improvement for state storage in account-based blockchains such as RSK, providing much better full-node performance. The Unitrie improves decentralization by reducing full node resource requirements, it improves transaction throughput by enabling better parallel execution of transactions, it prevents DoS attacks by caching payload sizes and reducing account sizes, it increases fairness by enabling better storage rent, and it reduces synchronization time by compressing the state.
We know that performing a network upgrade to use the Unitrie is challenging, but we think that the moment to pursue this change has arrived. RSK Labs is finishing the reference code, and adding the finishing touches to the RSKIPs while the RSK community is evaluating the change. In the upcoming months we expect a safe network upgrade to activate the Unitrie.